2.8 集群同步协调&状态管理
2.8.1 概述
大多数时候,dble结点是无状态的,所以可以用常用的高可用/负载均衡软件来接入各个结点。
这里不讨论各个负载均衡软件的使用。
主要讨论一下某些情况下需要同步状态的操作和细节。
注:本部分内容需要额外部署zookeeper用于管理集群的状态和同步。
2.8.2 相关配置
2.8.2.1 cluster.conf
以ZK为例
# 开启集群模式
clusterEnable=true
# 集群模式元数据中心为zk
clusterMode=zk
# zk地址
clusterIP=10.186.19.aa:2281,10.186.60.bb:2281
#zk为dble提供的根目录
rootPath=/dble
#本组dble的组名
clusterId=cluster-1
# 是否需要同步Ha状态
#needSyncHa=false
# 拉取一致性binlog线的超时时间
#showBinlogStatusTimeout=60000
#自增序列类型
sequenceHandlerType=2
#自增序列默认开始时间
#sequenceStartTime=2010-11-04 09:42:54
#自增序列类型为3时,instanceId是否由ZK生成
#sequenceInstanceByZk=true
2.8.2.2 bootstrap.conf
instanceName 实例名称,用于发起集群任务或者汇报自己完成集群任务的标记 instanceId (自增序列使用,根据类型范围为0到1023 或者0到511)
2.8.3 初始化状态
方式1.
通过执行脚本init_zk_data.sh方式将某个结点的配置文件等数据写入ZK,所有结点启动时都从ZK拉取配置数据。
方式2.
在第一个结点第一次启动时自动将自己的配置文件写入ZK,其他结点启动时从ZK拉取。
第一个结点的判定:用分布式锁抢占的方式,未抢占到结点会阻塞等待直到获取到分布式锁,如果此时初始化标记已经被设置,则从ZK拉取配置,否则将自己本地配置写入。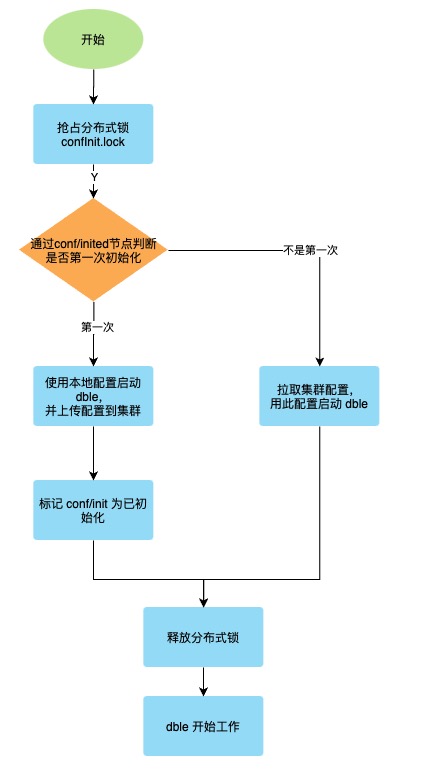
2.8.4 状态同步
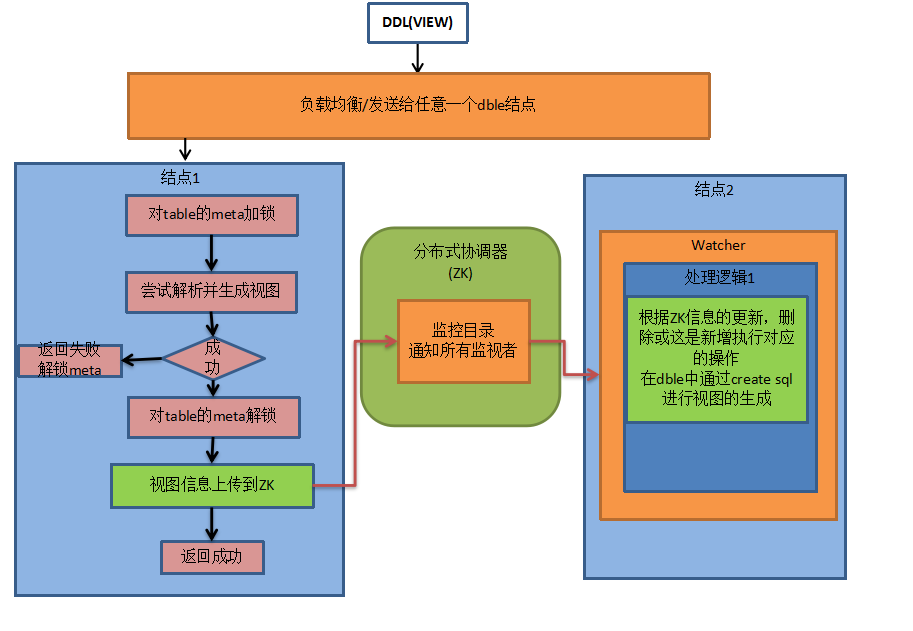
A.DDL
做DDL时候会在执行的某个节点成功后,将消息推给ZK,ZK负责通知其他结点做变更。流程如下图:
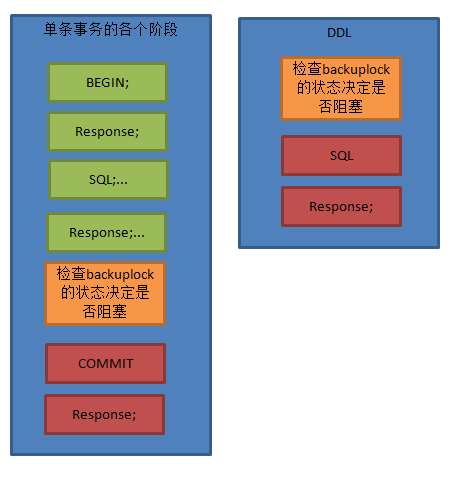
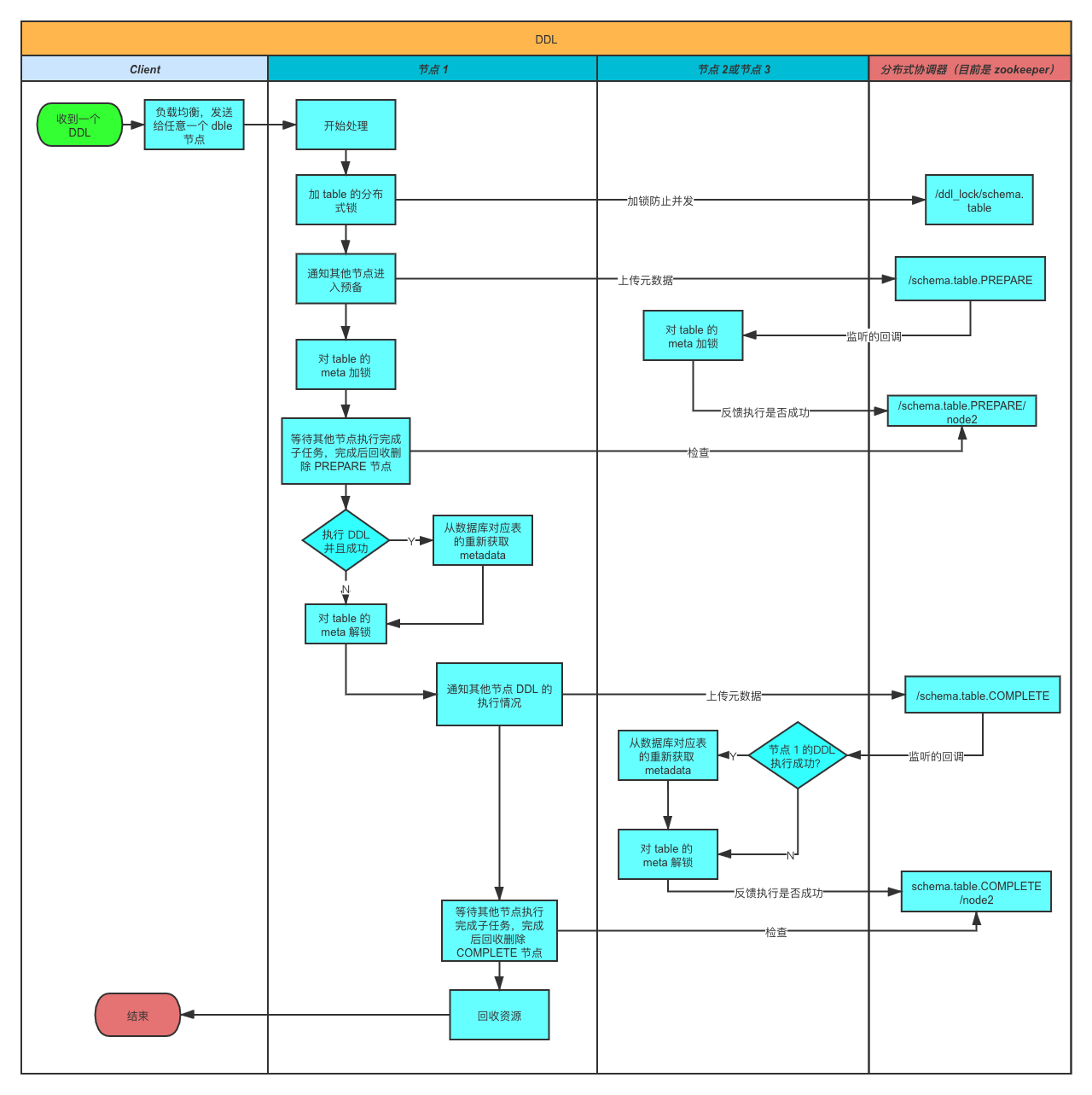 类似于二阶段按提交的方式
类似于二阶段按提交的方式
注:
- 新结点启动时,加载元数据前会检测是否有其他结点在做DDL变更,如果有,则等待。
否则加分布式锁防止加载元数据期间其他结点做DDL变更, 直到元数据加载完释放分布式锁 。
- "等待其他节点执行完成子任务" 指的是:每个节点完成任务后,都会创建子节点用来告知分布式协调器自己已经完成,执行主任务的节点负责检查所有结点是否都创建了子节点(即检查是否都完成了任务),如果完成则删除父结点(回收资源)。此操作为原子操作。
- 发起结点故障:如果执行DDL的结点故障下线,其他结点会侦听到此消息,保证解开对应结点的tablemeta锁,并记录故障告警(如果配置了告警通道),需要运维人工介入修改ZK对应ddl结点的状态,检查各个结点meta数据状态,可能需要reload metadata。
逻辑上不应该有某个监听节点上加载meta失败的情况,如果发生了,告警处理
(人工介入对应结点的meta是不正确的,需要reload meta)
- 注:view目前是异步模式,可能存在某个间隙view修改成功,查询仍旧拿到旧版的view结构。
B.reload @@config/ reload @@config_all
执行流程如下图:
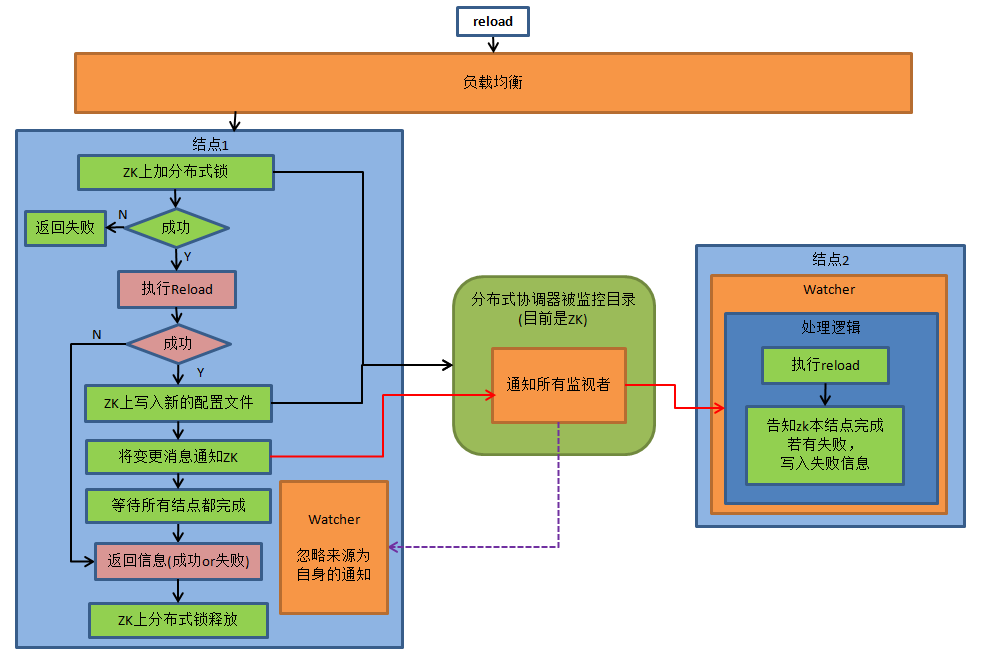
注:如果在部分结点失败,则会返回错误及错误原因以及结点名。 设计影响面:db.xml,sharding.xml, userxml ,sequence_conf.properties 和sequence_db_conf.properties
C.拉取一致性的binlog线
目的:
获得后端数据库实例的一致性binlog位置。由于两阶段提交的第二阶段执行在各结点无法保证时序性和同步性,所以直接下发show master status获取binlog可能会造成不一致。
实现方式:
如下图,当前端收到show @@binlog.status 语句时,遍历当前所有活动session查看状态 。
若session处于绿色区域,则在进入红色区域前等待知道show @@binlog.status结果返回
若存在session处于红色区域,则需要等待所有红色区域的session返回结果走出红色区域后下发show master status。
超时处理:
此处有可能有死锁发生。
场景:session1 正在更新tableA,处于绿色区域,session2下发有关于tableA 的DDL,等待 metaLock解锁,处于红色区域.session3 下发show @@binlog.status.
此时session1 等待session3, session2等待session1,session3等待session2.
因此引入超时机制。如果session3 等待超过showBinlogStatusTimeout(默认60s,可配置),自动放弃等待,环状锁解除。
集群协调:
1.收到请求后同步通知ZK,先等待本身结点准备工作结束,之后zk通知其他结点处理。
2.所有结点遍历各自的活动的session,进入红色区域的等待处理完成,绿色区域的暂停进入红色区域。
3.结点将准备好/超时将状态上报给ZK
4.主节点等待所有结点状态上报完成之后,判断是否可以执行任务,若是,则执行show @@binlog.status并返回结果,否则报告本次执行失败。
5.主节点通过ZK通知各结点继续之前的任务
集群超时处理:
若有结点超时未准备好,主节点会报超时错误,并通过ZK通知各结点继续之前的任务。
故障处理:
主节点执行过程中故障下线,其他结点会感知,保证自己结点一定时间后自动解锁继续原有任务。
ZK状态需要人工干预。人工等待所有结点超时之后,手动删除/修改zk上的状态信息以便下次执行时不出问题。
D.View管理
在使用集群模式是,使用zk进行view视图信息的管理,使得整个dble集群能够进行视图信息的同步 由于视图只用于数据查询且不会造成数据异常的属性,在视图同步时采用异步同步的方法
注 在zk上的view数据信息如下形式 key schema.table value {"serverId":"create_Server_id", "createSql":"view_create_sql"}
E.online状态
dble启动时候会在online的目录下注册自己的信息,如果此时正在做DDL,会阻塞一段时间,防止表结构元数据不一致。
功能:
1.作为集群协调时候检查哪些dble完成了对应任务的标准
2.dble故障后同集群的其他实例会发现状态并处理完收尾的状态,主要是DDL状态残留,拉取一致性binlog线或者暂停流量的残余。
F.高可用命令同步
当启用needSyncHa时候,此选项才生效
F.1 disable工作流程:
1.申请分布式锁
2.本地执行disable
3.将信息写入集群
4.等待所有结点完成disable
5.完成并清理
6.释放分布式锁
F.2 enable工作流程:
1.申请分布式锁
2.本地执行enable
3.将信息写入集群
4.释放分布式锁
5.其他订阅结点异步完成enable
F.3 switch工作流程:
1.申请分布式锁
2.本地执行switch
3.将信息写入集群
4.释放分布式锁
5.其他订阅结点异步完成switch
G.暂停流量(一般用于扩容迁移等)
G.1 pause流程
- 申请分布式锁 pause_node.lock
- 通知其他结点
- 本结点停流量
- 等待其他结点完成停流量 或者超时
- 返回暂停成功或者失败
- 释放分布式锁
G.2 resume流程
- 申请分布式锁 pause_node.lock
- 本结点恢复流量
- 通知其他结点
- 等待其他结点完成恢复流量 或者超时
- 返回暂停成功或者失败
- 释放分布式锁
2.8.5 XA日志管理
在使用集群模式时,未完成的XA日志会存放在zookeeper上,更加安全,防止某台机器硬盘物理损坏导致日志丢失(此处可能会有并发高吞吐引发的性能及其他问题,待测试)。
2.8.6 ZK整体目录结构
rootPath(配置在cluster.cnf中的)
clusterId(配置在cluster.cnf中的)
conf
inited
status
operator
instanceName(临时的,key为bootstrap.cnf配置内容。功能:reload响应id)
sharding(sharding.xml的json信息)
db(db.xml的json信息)
user(user.xml的json信息)
migration(用于暂停流量)
pause
instanceName(临时的,key为bootstrap.cnf配置内容。功能:响应结点)
resume
instanceName(临时的,key为bootstrap.cnf配置内容。功能:响应结点)
sequences
instanceid //zk 分布式方式
incr_sequence//批量步长方式
table_name
common(sequence_conf.properties 或者sequence_db_conf.properties)
binlog_pause
status (发生时建立,结束后回收)
instanceName(临时的,key为bootstrap.cnf配置内容。功能:响应结点)
lock
syncMeta.lock(临时的,启动时防止元数据变更)
confInit.lock
confChange.lock
binlogStatus.lock
ddl_lock/schema.table
view_lock/`schema`.`table`
dbGroup_locks/groupName
pause_node.lock
online
instanceName(临时的,key为bootstrap.cnf配置内容。)
ddl
schema.table.PREPARE(ddl操作的第一阶段,用于加锁)
instanceName(临时的,key为bootstrap.cnf配置内容。功能:响应结点)
schema.table2.COMPLETE(ddl操作的第二阶段,此时 ddl 已执行完成,开始同步元数据)
instanceName(临时的,key为bootstrap.cnf配置内容。功能:响应结点)
schema.table3.PREPARE
xalog
node1
node2
view
schema:view
operator (订阅目录)
schema.view:(update/delete,注意:create当作update处理)
instanceName(临时的,key为bootstrap.cnf配置内容。功能:响应结点)
dbGroups
dbGroup_status
groupName
dbGroup_response
instanceName(临时的,key为bootstrap.cnf配置内容。功能:响应结点)
2.8.7 全局序列
类twitter snowflake 方式,ZK完成的工作是生成每个节点的instanceID。
类offset-step 方式,ZK完成的工作是存储当前的Step值。
2.8.9 移除集群中分布式锁的方式
前置知识
当clusterMode=ucore (使用爱可生商业集群调度中心), 使用ucore集群调度中心的分布式锁是有超时机制的;dble内部为了防止使用期间超时,内部会给分布式锁分别创建一个线程(renewThread),专门用来续约对应分布式锁,防止锁超时。
clusterMode=zk,zk集群调度中心的分布式锁没有超时机制,则不用创建renew线程。
可检索 续约日志:renew lock of session success
背景
在某些不可预测的情况下,可能会导致分布式锁残留,导致dble内部的renew线程一直工作,比如conf reload的场景;希望能通过不重启的方式实现renew线程自杀,最终达到分布式锁超时而被释放的效果。
查看renew线程列表
在管理端侧,查看dble_cluster_renew_thread表,此表展示当前时间点正在做分布式操作时获取分布式锁对应的renew线程列表,如:
mysql> select * from dble_cluster_renew_thread;
+-------------------------------------------------------------------+
| renew_thread |
+-------------------------------------------------------------------+
| UCORE_RENEW_universe/dble-v3/ushard-1/lock/ddl_lock/testdb.tablea |
+-------------------------------------------------------------------+
2 rows in set (0.00 sec)
注意:非集群模式下 或者 集群模式不为ucore时,查询的结果为空;
采用kill renew线程
mysql> kill @@cluster_renew_thread 'UCORE_RENEW_universe/dble-v3/ushard-1/lock/confChange.lock';
Query OK, 0 rows affected (0.00 sec)
kill cluster renew thread successfully!
可检索 kill日志:manual kill cluster renew thread
注意:在实际实现中,并不是在集群调度中心里直接把对应的分布式锁删除,而是通过中断dble内部renew线程,实现不再对分布式锁续约,达到分布式锁最终因超时而自行释放。
2.8.10 附录